As you already know, the fixed-length data and the internal attributes of a row must fit into a single page. Fortunately, SQL Server can store the variable-length data on different data pages. There are two different ways to store the data, depending on the data type and length.
ROW_OVERFLOW storage
SQL Server stores variable-length column data, which does not exceed 8,000 bytes, on special pages called ROW_OVERFLOW pages. Let’s create a table and populate it with the data shown in listing below.
create table dbo.RowOverflow
(
ID int not null,
Col1 varchar(8000) null,
Col2 varchar(8000) null
);
insert into dbo.RowOverflow(ID, Col1, Col2)
values (1,replicate('a',8000),replicate('b',8000));
SQL Server creates the table and inserts the data row without any errors, even though the data row size exceeds 8,060 bytes. Let’s look at the table page allocation using the DBCC IND command.
DBCC IND('SqlServerInternals','dbo.RowOverflow',-1)

01. ROW_OVERFLOW data: DBCC IND results
Now you can see two different sets of IAM and data pages. The data page with PageType=3 represents the data page that stores ROW_OVERFLOW data.
Let’s look at data page 214647, which is the in-row data page that stores main row data. The partial output of the DBCC PAGE command for the page (1:214647) is shown below.
Slot 0 Offset 0x60 Length 8041 Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS Record Size = 8041 Memory Dump @0x000000000FB7A060
0000000000000000:30000800 01000000 03000002 00511f69 9f616161 0............Q.iŸaaa 0000000000000014:61616161 61616161 61616161 61616161 61616161 aaaaaaaaaaaaaaaaaaaa 0000000000000028:61616161 61616161 61616161 61616161 61616161 aaaaaaaaaaaaaaaaaaaa 000000000000003C:61616161 61616161 61616161 61616161 61616161 aaaaaaaaaaaaaaaaaaaa 0000000000000050:61616161 61616161 61616161 61616161 61616161 aaaaaaaaaaaaaaaaaaaa <Skipped> 0000000000001F2C:61616161 61616161 61616161 61616161 61616161 aaaaaaaaaaaaaaaaaaaa 0000000000001F40:61616161 61616161 61616161 61616161 61020000 aaaaaaaaaaaaaaaaa... 0000000000001F54:00010000 00290000 00401f00 00754603 00010000 .....)...@...uF..... 0000000000001F68:00
As you see, SQL Server stores Col1 data in-row. Col2 data, however, has been replaced with a 24-byte value. The first 16 bytes are used to store off-row storage metadata attributes, such as type, length of the data, and a few other attributes. The last 8 bytes is the actual pointer to the row on the row-overflow page, which is the file, page, and slot number. Figure below shows this in detail. Remember that all information is stored in byte-swapped order.
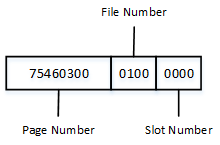
02. ROW_OVERFLOW page pointer
As you see, the slot number is 0, file number is 1, and page number is the hexadecimal value 0x00034675, which is decimal 214645. The page number matches the DBCC IND results shown earlier in the post.
The partial output of the DBCC PAGE command for the page (1:214645) is shown below.
Blob row at: Page (1:214645) Slot 0 Length: 8014 Type: 3 (DATA) Blob Id:2686976 0000000008E0A06E: 62626262 62626262 62626262 62626262 bbbbbbbbbbbbbbbb 0000000008E0A07E: 62626262 62626262 62626262 62626262 bbbbbbbbbbbbbbbb 0000000008E0A08E: 62626262 62626262 62626262 62626262 bbbbbbbbbbbbbbbb
Col2 data is stored in the first slot on the page.
LOB Storage
For the text, ntext, or image columns, SQL Server stores the data off-row by default. It uses another kind of page called LOB data pages. You can control this behavior by using the “text in row” table option. For example, exec sp_table_option dbo.MyTable, ‘text in row’, 200 forces SQL Server to store LOB data less or equal to 200 bytes in-row. LOB data greater than 200 bytes would be stored in LOB pages.
The logical LOB data structure is shown below.
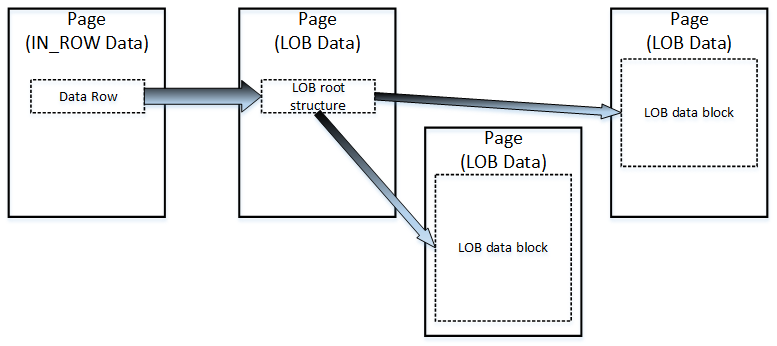
03: LOB data structure
Like ROW_OVERFLOW data, there is a pointer to another piece of information called the LOB root structure, which contains a set of the pointers to other data pages/rows. When LOB data is less than 32 KB and can fit into five data pages, the LOB root structure contains the pointers to the actual chunks of LOB data. Otherwise, the LOB tree starts to include an additional, intermediate level of pointers, similar to the index B-Tree.
Let’s create the table and insert one row of data there.
create table dbo.TextData
(
ID int not null,
Col1 text null
);
insert into dbo.TextData(ID, Col1)
values (1, replicate(convert(varchar(max),'a'),16000));
The page allocation for the table is shown below.

04. LOB data: DBCC IND results
As you see, the table has one data page for in-row data and three data pages for LOB data. I am not going to examine the structure of the data row for in-row allocation; it is similar to the ROW_OVERFLOW allocation. However, with the LOB allocation, it stores less metadata information in the pointer and uses 16 bytes rather than the 24 bytes required by the ROW_OVERFLOW pointer.
The result of DBCC PAGE command for the page that stores the LOB root structure is shown below.
Blob row at: Page (1:3046835) Slot 0 Length: 84 Type: 5 (LARGE_ROOT_YUKON) Blob Id: 131661824 Level: 0 MaxLinks: 5 CurLinks: 2 Child 0 at Page (1:3046834) Slot 0 Size: 8040 Offset: 8040 Child 1 at Page (1:3046832) Slot 0 Size: 7960 Offset: 16000
As you see, there are two pointers to the other pages with LOB data blocks, which are similar to the blob data stored in ROW_OVERFLOW pages.
The format, in which SQL Server stores the data from the (MAX) columns, such as varchar(max), nvarchar(max), and varbinary(max), depends on the actual data size. SQL Server stores it in-row when possible. When in-row allocation is impossible, and data size is less or equal to 8,000 bytes, it stored as ROW_OVERFLOW data. The data that exceeds 8,000 bytes is stored as LOB data.
It is also worth mentioning that SQL Server always stores rows that fit into a single page using in-row allocations. When a page does not have enough free space to accommodate a row, SQL Server allocates a new page and places the row there rather than placing it on the half-full page and moving some of the data to ROW_OVERFLOW pages.
SELECT * and I/O
There are plenty of reasons why selecting all columns from a table with the select * operator is not a good idea. It increases network traffic by transmitting columns that the client application does not need. It also makes query performance tuning more complicated, and it introduces side effects when the table schema changes.
It is recommended that you avoid such a pattern and explicitly specify the list of columns needed by the client application. This is especially important with ROW_OVERFLOW and LOB storage, when one row can have data stored in multiple data pages. SQL Server needs to read all of those pages, which can significantly decrease the performance of queries.
As an example, let’s assume that we have table dbo.Employees with one column storing employee pictures.
create table dbo.Employees
(
EmployeeId int not null,
Name varchar(128) not null,
Picture varbinary(max) null
);
;WITH N1(C) AS (SELECT 0 UNION ALL SELECT 0) -- 2 rows
,N2(C) AS (SELECT 0 FROM N1 AS T1 CROSS JOIN N1 AS T2) -- 4 rows
,N3(C) AS (SELECT 0 FROM N2 AS T1 CROSS JOIN N2 AS T2) -- 16 rows
,N4(C) AS (SELECT 0 FROM N3 AS T1 CROSS JOIN N3 AS T2) -- 256 rows
,N5(C) AS (SELECT 0 FROM N4 AS T1 CROSS JOIN N2 AS T2) -- 1,024 rows
,IDs(ID) AS (SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM N5)
insert into dbo.Employees(EmployeeId, Name, Picture)
select
ID
,'Employee ' + convert(varchar(5),ID)
,convert(varbinary(max),replicate(convert(varchar(max),'a'),120000))
from Ids;
The table has 1,024 rows with binary data of 120,000 bytes. Let’s assume that we have code in the client application that needs the EmployeeId and Name to populate a drop-down box. If a developer is not careful, he can write a select statement using the select * pattern, even though a picture is not needed for this particular use-case.
Let’s compare the performance of two selects; one selecting all data columns and another that selects only EmployeeId and Name.
set statistics io on set statistics time on select * from dbo.Employees; select EmployeeId, Name from dbo.Employees; set statistics io off set statistics time off
Results: select EmployeeId, Name from dbo.Employee: Number of reads: 7; Execution time (ms): 2 select * from dbo.Employee Number of reads: 90,895; Execution time (ms): 343
As you see, the first select, which reads the LOB data and transmits it to the client, is a few orders of magnitude slower than the second select.
One case where this becomes extremely important is with client applications, which use Object Relational Mapping (ORM) frameworks. Developers tend to reuse the same entity objects in different parts of an application. As a result, an application may load all attributes/columns even though it does not need all of them in many cases.
It is better to define different entities with a minimum set of required attributes on an individual use-case basis. In our example, it would work best to create separate entities/classes, such as EmployeeList and EmployeeProperties. An EmployeeList entity would have two attributes: EmployeeId and Name. EmployeeProperties would include a Picture attribute in addition to the two mentioned.
This approach can significantly improve the performance of systems.
Next: Allocation Maps
Pingback: SQL Server Storage Engine: LOB Storage | My Lov...
Pingback: SQL Server Storage Engine: LOB Storage | SQL Se...
Pingback: LOB and Extra Page Storage Generally | Sladescross's Blog
Pingback: Viewing the size of your database objects « Sunday morning T-SQL
Very elucidate article!
I’m still not convinced for not using SELECT *. In a table with many fields when we only need a few, for sure * is a waste. But what about when we do need all the fields?
The problem when the client is an app is that developers rather reuse code. So for each entity we develop a set of CRUDQ functions in a DAO, and reuse them whenever needed. It’s not wise to have multiple CRUDQ functions, one for each need. The software gets bigger, and also harder to maintain and change.
If I can have at a maximum 2 DAO functions for each CRUDQ operation, I’d accept doing it. More than that, I’d rather split a big table into 2 or more 1:1 tables and join them when needed.
Hi Hikari,
Another problem with SELECT * is supportability. What will happen when there are new columns added to the database in the future and application does not know/need them and/or when column is dropped? I’d say that the cost of referencing all columns directly in the SELECT statement is not significant – after all it is only typing comparing to the potential overhead you’d have on every call.
I’ve also seen numerous examples of how the same entity object is reused for multiple use-cases – for example in lists/grids and a single-row property screen. This one is the bigger issue – you potentially load multiple unnecessary attributes at once even if you do not need them in some of use-cases. This could be the major performance hit, which also makes index tuning very complicated.
Obviously, there is no such thing as the silver bullet. But it is always better to reduce the load to the DB server whenever it is possible.
Sincerely,
Dmitri