SQL Server supports two data types to store spatial information – geometry and geography. Geometry supports planar, or Euclidean, flat-earth data. Geography supports ellipsoidal round-earth surface. Both data types can be used to store location information, such as GPS latitude and longitude coordinates. Geography data type considers Earth roundness and provides slightly better accuracy although it has stricter requirements to the data. As a couple of examples, data must fit in the single hemisphere and polygons must be defined in specific ring orientation.
Storing location information in geometry data type introduces its own class of problems. It works fine and often has better performance than geography data type. Although, we cannot calculate the distance between points – the unit of measure for result is decimal degrees, which are useless in non-flat surface.
Let’s take a look at spatial data type performance in one of the specific use-cases, such as distance calculation between two points. Typical use-case for that scenario is the search for the point of interest (POI) close to specific location. First, let’s create three different tables storing POI information in the different format and populate them with some data.
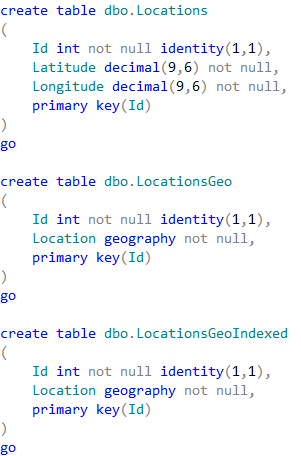
01. Test tables
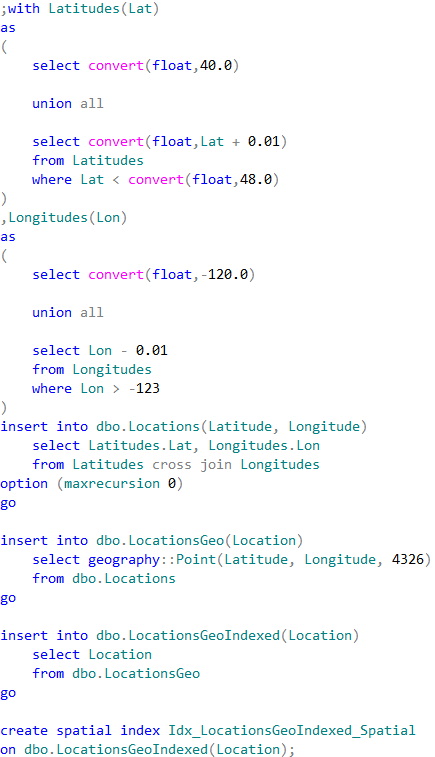
02. Populating test tables with data
The first table dbo.Locations stores the coordinates using decimal(9,6) data type. Two other tables are using geography data type. Finally, the table dbo.LocationsGeoIndexed has Location column indexed with special type of the index called spatial index. Those indexes help improving performance of some operations, for example distance calculation or check if objects are intersecting.
It is worth mentioning that the first table uses decimal(9,6) data type rather than float. This decision saves us six bytes per pair of values and provides the accuracy that exceed the accuracy of commercial-grade GPS receivers.
Let’s run the tests that measures performance of the queries that calculate the number of locations within one mile from Seattle City Center. In case of dbo.Locations table, we will use dbo.CalcDistanceCLR function, which we defined earlier. For two other tables we will call spatial method STDistance.
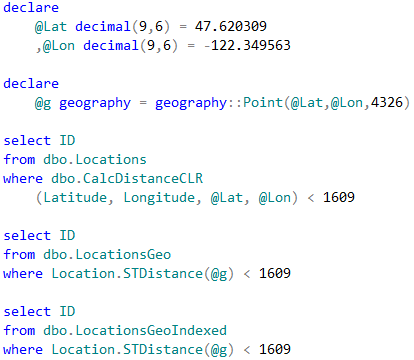
03. Test queries (table-wide lookup)
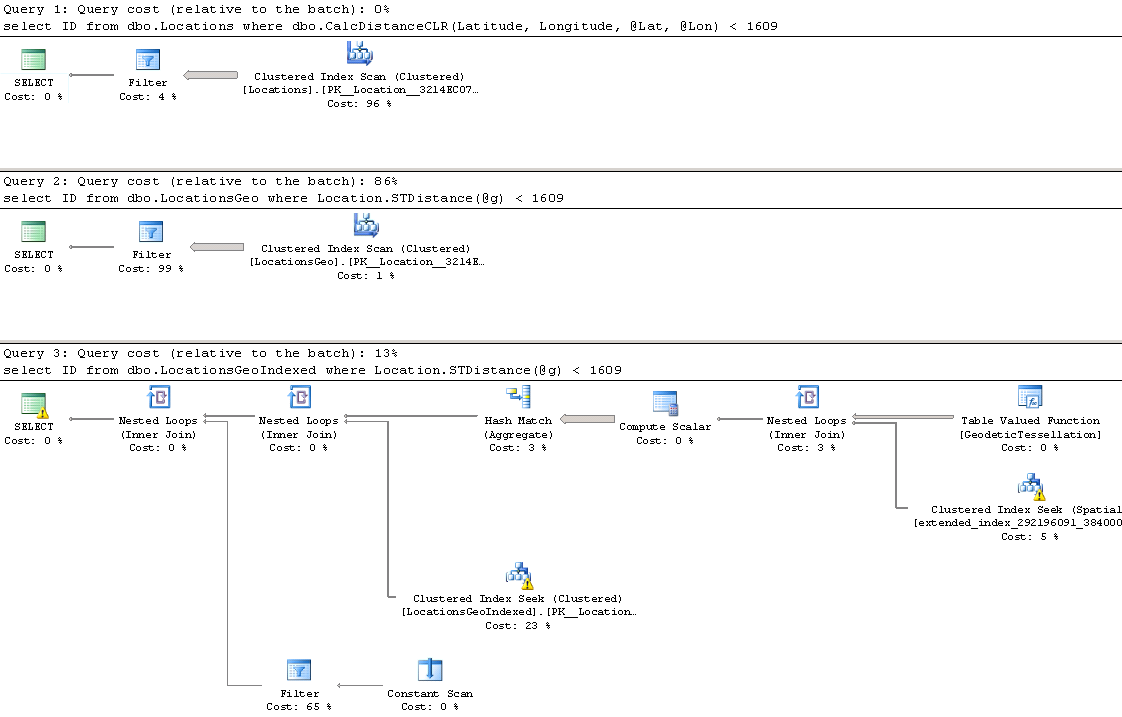
04. Execution plans (table-wide lookup)
The first and second queries perform clustered index scan and calculate the distance for every row from the table. Last query uses spatial index to lookup such rows. We can see execution times for the queries in the table below.
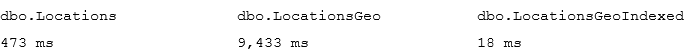
05. Execution time (Table-wide lookup)
As we see, spatial index greatly benefits the query. It is also worth mentioning, that without the index, performance of CalcDistanceCLR method is better comparing to STDistance.
Although spatial index greatly improves the performance, it has its own limitations. It works in the scope of entire table and all other predicates are evaluated after spatial index operations. That can introduce suboptimal plans in some cases.
As the example, let’s look at the use-case, when we store POI information on company-by-company basis .

06. Test table creation (company-wide lookup)
In case, when we perform POI lookup for specific company, CompanyId column must be included as the predicate to the queries. SQL Server has two choices how to proceed. The first choice is clustered index seek based on CompanyId value calling STDistance method for every POI that belongs to the company. Another choice is using spatial index, find all POIs within the specified distance regardless of what company they belong and, finally, join it with the clustered index data. Let’s run those queries.
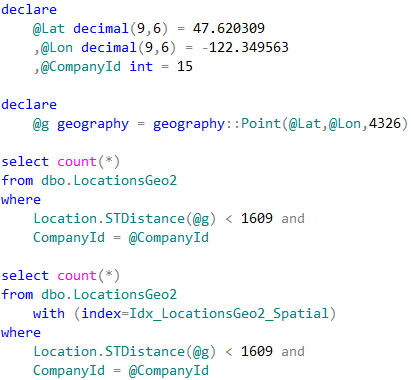
07. Test queries (company-wide lookup)
Neither method is efficient in case when table stores the large amount of data for the large number of companies. Execution plan of the first query utilizing clustered index seek shows that it performed STDistance call 241,402 times – once per every company POI.

08. Execution plan (clustered index seek approach)
The execution plan for the second query shows that spatial index lookup returned 550 rows – all POI in the area, regardless of what company they belong. SQL Server had to join the rows with the clustered index before evaluating CompanyId predicate.

09. Execution plan (Spatial index approach)
One of the ways to solve such problem called Bounding Box approach. That method allows us to minimize the number of the calculations by filtering out POIs that are outside of the area of interest.
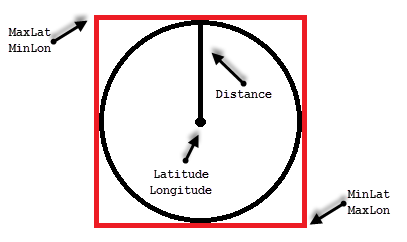
10. Bounding box
All points we need to select residing in the circle with location as the center point and radius specified by the distance. The only points we need to evaluate are residing within the box that inscribes that circle.
We can calculate the coordinates of the corner points of the box, persist it in the table and use regular non-clustered index to pre-filter the data. This would allow us to minimize the number of expensive distance calculations to perform.
Calculation of the bounding box corner points can be done with CLR table-valued function shown below.
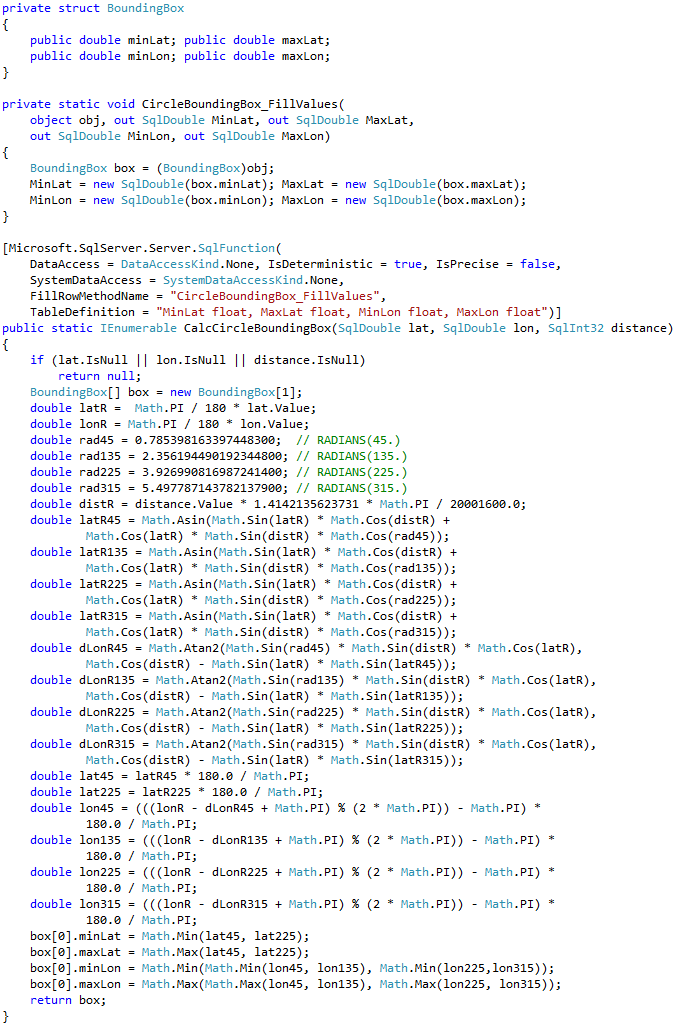
11. Calculating bounding box corner points
Let’s alter our table and add bounding box points. We also need to create non-clustered index to support our query.
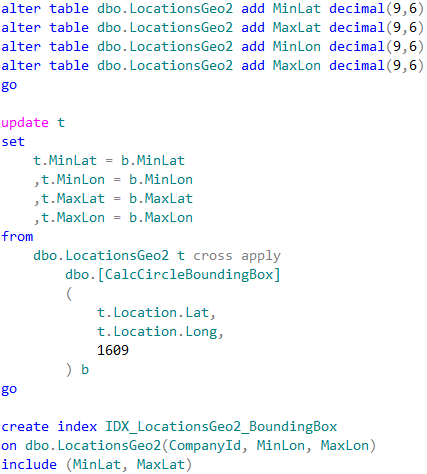
12. Table alteration (adding bounding box corner points)
Now, we can change the query to utilize the bounding box.
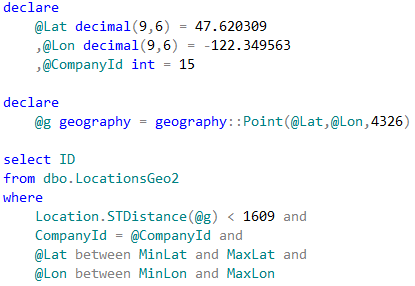
13. Query utilizing bounding box

14. Query utilizing bounding box (Execution plan)
As we see, last query calculated the distance 15 times. This is significant improvement comparing to 241,402 calculations from the original query. The execution times are shown below:

15. Execution time (Company-wide lookup)
As we see, bounding box outperforms both – clustered index seek and spatial index lookup. Obviously, it would be the case only when bounding box reduces the number of the calculations to degree that offsets the overhead of non-clustered index seek and key lookup operations. It is also worth mentioning that we do not need spatial index with such approach.
We can use bounding box for the other use-cases. For example, when we are checking if position belongs to the area defined by the polygon. Bounding box corner coordinates should store minimum and maximum latitude/longitude of the polygon corner points. Similarly to the distance calculation, we would filter-out the locations outside of the box before performing expensive spatial method call that validates if point is within the polygon area.
Source code is available for download
Pingback: (SFTW) SQL Server Links 06/09/13 • John Sansom
My english is not so good. Excellent your solution! Thanks a lot! A question. Is there a CLR to calculate a toute deviation? For example: is a have a route of many coordinates x and y calculate the distance between another coordinates in relation to the route to determine if a driver exit the route some quantity of meters.
Hi Julio,
Unfortunately, standard functional does not support it. Technically, you can do the following:
1. Define route as Line
2. Convert it to polygon specifying deviation using STBuffer method
3. Check for the positions, which are outside of polygon using STWithin method.
This would work but would be very slow.
Sincerely,
Dmitri
This is interesting, I like the bounding box idea. You can achieve similar results if your primary key is clustered and stores the data in order of proximity. I fooled around with this for a while since we have a static set of zip codes which we group based on proximity to a single poi. The poi’s are generated quickly as the result of an upload though often 10,000 at a time. I found the performance issue of creating the radius and calculating the bounding box greatly outweighed the performance benefits so I looked for alternatives. I ended up using center lat and center long as the basis of the clustered index however, I don;t think that is the best possible idea. I tried storing them in a spiral by calculating their distance from a central point but that was slower, The idea is to store them in an order so they are close to each other in the physical table. Since they are zip codes, ordering them by zip code seemed like a good plan but center lat and long is faster.
Hi Charles,
Interesting approach!
Obviously everything depends on the use-cases. Would love to know more about your solution!
Dmitri
Couldn’t for the life of me get a geography query to be performant when comparing larger data sets of 1+ million records – but cut the time down from 15+ minutes to 38 seconds using spatial indexing – you’re a hero!
Thank you, Graham!