Yesterday we had the discussion during Tampa Bay SQL Server User Group meeting regarding the size of variable width columns. The question was if it matters how to define such columns – for example if column holds 100 characters should it be defined as varchar(100), varchar(1000) or varchar(max).
The answer is not so simple. From the storage prospective it does not really matter. Row stores actual data size + 2 bytes in offset array. The question though is how it affects performance.
When Query Optimizer generates the query plan, it needs to estimate how much memory needed for the query execution. It estimates the number of rows returned by each specific iterator (the valid statistics is the key) as well as the row size. And this is where it comes to play. SQL Server does not know if varchar(100) column holds in average 1 character or 100 characters. So it uses simple assumption – 50% of declared column size and 4000 bytes for (max) columns.
Correct estimate is especially critical for sort and hash operations – if operation cannot be done in memory, Sql Server flushes the data to tempdb and do the operations there. And this is the major performance hit. Let’s see this in action.
Let’s create the table with 2 varchar fields – 100 and 210 characters and populate this table with 1M rows. Let’s put 100 characters into both varchar fields.
create table dbo.Varchars
(
ID int not null,
Field1 varchar(100) not null,
Field2 varchar(210) not null,
primary key (ID)
)
go
declare
@I int = 0
begin tran
while @I < 1000000
begin
insert into dbo.Varchars(ID, Field1, Field2)
values(@I,REPLICATE(CHAR(65 + @I % 26),100),REPLICATE(CHAR(65 + @I % 26),100))
select @I += 1
end
commit
Now let’s run a few tests. Let’s run SQL Profiler and trace “Sort Warning” event. That event basically tells us when data is flushed to TempDb for the sorting purposes. Let’s run the simple query:
declare @A varchar(1000)
select @A = Field1
from dbo.Varchars
where ID < 42000
order by Field1
Let’s look at the Query Plan – as you see row size estimated incorrectly.
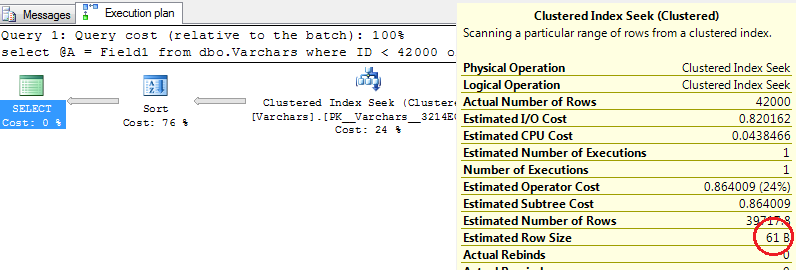
We also can see Sort Warning in SQL Profiler

Finally – we can see that query uses 6656Kb

Let’s run the second query:
declare @A varchar(1000)
select @A = Field2
from dbo.Varchars
where ID < 42000
order by Field2
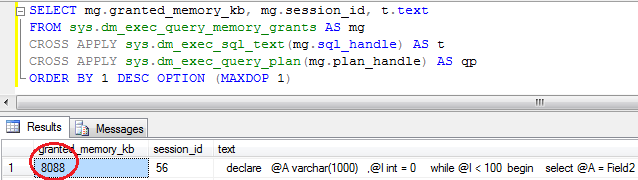
Same query plan but different row size.

No Sort Warnings in SQL Profiler. As for the memory, this query uses 8088K.
Finally let’s run it 100 times in the loop and compare the execution statistics:

As you can see the first query is 25% slower than the second one. This is quite simple example – with complex queries the difference could be dramatic.
So on one hand it looks like that it’s good idea to always define variable width columns really wide. On other hand it introduces the different problem – you don’t want to overestimate row size. It will lead to the bigger memory consumption as well as waits for the large memory grants could be longer than to the small ones. I would suggest to define those columns in about 2 times bigger than actual average data size, so row size estimate would be as accurate as possible.