Today I would like us to talk about the special case of the deadlock called key lookup deadlock. This deadlock can happen when multiple sessions are reading and updating the same rows simultaneously. Let us look at the example.
As the first step, let us create the table with the clustered and nonclustered indexes. Nonclustered index has one included column. We are inserting 256 rows there keeping clustered and nonclustered key values the same – from 1 to 256.
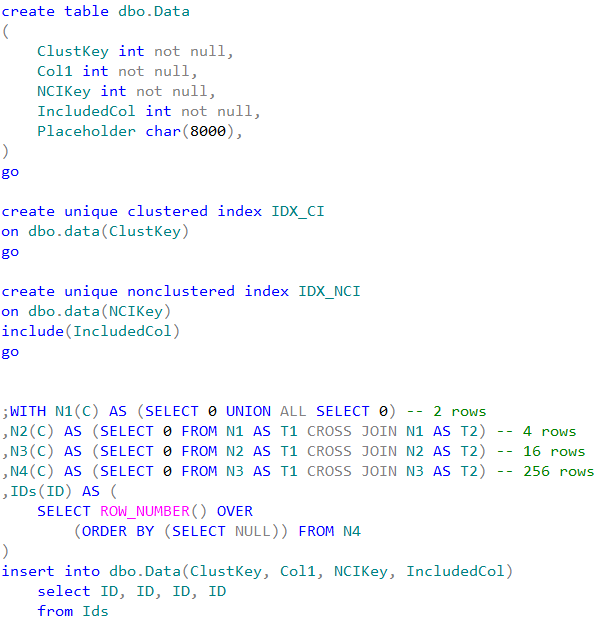
Creating the table and populating it with the data
Now let us run two sessions in parallel. In the first session, we are updating the column that included to the nonclustered index using clustered key value in where clause.
Session 1 code
As we can guess, this session will use clustered index seek operation in the execution plan.

Session 1 execution plan
The second session will read the same row using nonclustered key value

Session 2 code
Because Col1 is not part of the nonclustered index, we would have nonclustered index seek and key lookup operations in the execution plan:
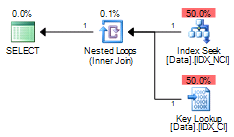
Session 2 execution plan
Both statements are running in the loop just to emulate concurrent access to the data. In just a few seconds, we will have the deadlock and session with select would be chosen as the deadlock victim.
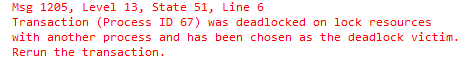
Deadlock error
At the first glance, this looks confusing. Both sessions are dealing with the same row. We would expect to have the blocking cases due to exclusive (X) and shared (S) lock incompatibility for the duration of the transaction although we do not expect the deadlock. However, even if we are dealing with the single row, there are two indexes involved.
Let us take a look what locks SQL Server acquires when the table has the multiple indexes. First, let us update the column, which does not belong to nonclustered index, and see what row-level locks will be held.

Updating column that is not part of the nonclustered index
As we see, there is only one exclusive (X) lock on the clustered index. Col1 is not part of nonclustered index and as result, SQL Server does not need to update it and acquire the lock there.
Let us see what happen, if we update the column, which is included to the nonclustered index.

Updating column that is included to the nonclustered index
As we see, now we have two locks in place – one on each index key. And the point here is that we run such update, SQL Server would lock the row in one index first and another index after that. The sequence depends on the execution plan and in our case it would acquire exclusive (X) lock on the clustered index first.
Similarly, our select statement also acquires two shared (S) locks. First, it would lock the row in non-clustered index and then acquire the lock on the clustered index during key lookup operation.
That should give us the idea why we have the deadlock. Both statements are running simultaneously. In the first step, update statement acquires exclusive (X) lock on the row in the clustered index and select statement acquires shared (S) lock on the row in the nonclustered index
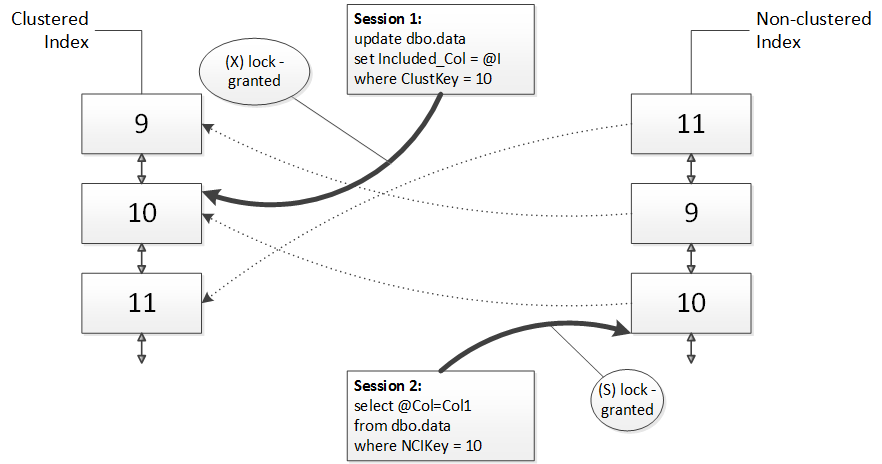
Key lookup deadlock: Step 1
After that, update statement is trying to acquire the exclusive (X) lock on the nonclustered index row and being blocked because there is the shared (S) lock held. Same thing happens with select statement, which is trying to acquire shared (S) lock on the clustered index row and being blocked because of the exclusive (X) lock held. Classic deadlock.
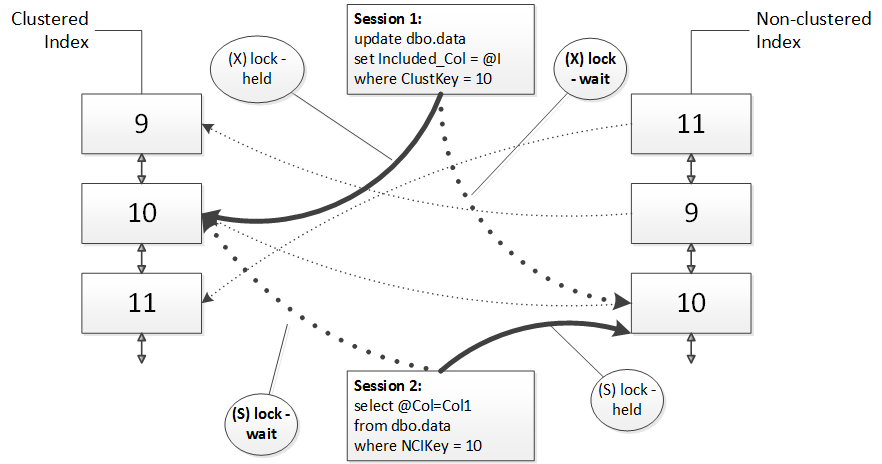
Key lookup deadlock: Step 2
To prove that, we can run the statement that shows the current row-level locks immediately after we run our original two sessions. If we are lucky, we can catch the state when both sessions are blocked before deadlock monitor task wakes up and terminate one of the sessions.
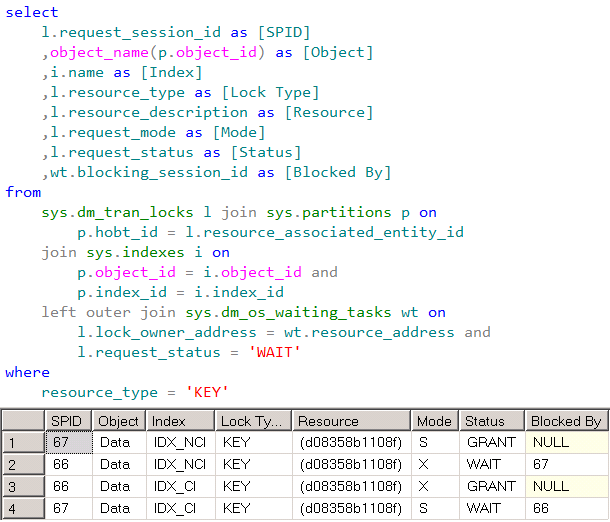
Row-level locks in time of the deadlock
There are a few ways that can help to eliminate the deadlock. First option would be eliminating key lookup operation by adding Col1 as included column to the index. In such case, select statement does not need to access the data from the clustered index, which will solve the problem. Unfortunately, that solution increases the size of the nonclustered index key row and introduce additional overhead during data modifications and index maintenance.
Another approach would be switching to optimistic isolation levels where writers do not block readers. While it can help to solve blocking and deadlocking issues, it would also introduce additional tempdb overhead and increases the fragmentation.
Finally, we can refactor the code and separate nonclustered index seek and key lookup operations to two separate selects

Workaround: separating NCI seek and key lookup

Workaround: Execution plan
Both select statements are working on the single index scope and as result would not hold shared (S) locks on the both indexes simultaneously when we are using read committed transaction isolation level. Although, this solution would not work in repeatable read and serializable isolation levels where shared (S) locks held until the end of the transaction.
Source code is available for download
Hi,
Interesting test case. By the way, I think the snapshot for the the second session’s code is not quite right: the “SELECT @COL1 …. ” statement isn’t there.
Hi Andy,
Yes, put the link to the wrong picture. Thank you for the catch!
Sincerely,
Dmitri
Pingback: Something for the Weekend - SQL Server Links 12/07/13 • John Sansom
Excellent series! Very much worth reading. Thanks
Pingback: Deadlocks in SQL Server | Database Skills
Pingback: Deadlocks in Microsoft Sql Server, some quick resolutions and Oracle comparison | Massimo Tinelli
I’ve always thought at this as a bug in SQL Server. I understand inherently why the problem happens (as you’ve described it), and I don’t have an awesome solution, but it also seems stupid that the optimiser gets itself into this situation.
Hi Cody,
Well, there is no easy solution here if we think about pessimistic concurrency. Locking data across multiple indexes would be worse for the blocking.. So it is what it is 🙂
Sincerely,
Dmitri
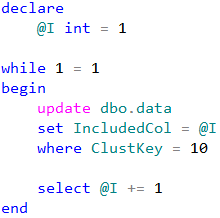
Dmitri,
As a variation, I tried 2 separate transactions. The first updates the IncludedCol using the Clustered Index Seek:
begin tran
update dbo.Data
set IncludedCol = 10
where ClustKey = 10;
This puts an eXclusive lock on the Clustered Index row, but not the IDX_NCI row, presumably because the IncludedCol value was already 10, so the transaction did not lock this row.
Leaving this first transaction uncommitted, I then ran the select statement using the Non-Clustered Index Seek and Key Lookup:
begin tran
select Col1
from dbo.Data
where NCIKey = 10
Since the 1st transaction did not lock the IDX_NCI row, it did not wait for a shared lock on this row. Since the 1st transaction still held the eXclusive lock on the IDX_CI row, I expected this 2nd transaction to block and wait for a Shared lock on this row. This is what happens at the repeatableread and/or serializable levels, but NOT the readcommitted level.
I am not sure why the 2nd transaction does not block on the Key Lookup at the readcommitted level. Perhaps there is a cached plan it is reading Col1 from?
Hi Andy,
Do you have READ_COMMITTED_SNAPSHOT database option enabled? If this is the case, SELECT would read the last committed version from tempdb version store and would not acquire (S) lock in READ COMMITTED.
Sincerely
Dmitri
Dmitri,
Thank you so very much for responding. I also thought of the READ_COMMITTED_SNAPSHOT option. It is not enabled for the database on my system, even though this example is behaving exactly as though it is enabled.
I am still investigating. I will post back here when I find the solution.
Thank you very much,
Andy
Closing the loop (publicly)
The update statement does not acquire (X) on NCI because, technically, it did not modify the data. It will change if you use any other value for IncludedCol and indexes will be actually modified.
On SELECT – it seems that there is some internal attribute in lock structure, that indicates such condition – e.g. no data had been modified. And it seems that there is an optimization in READ COMMITTED, which detects such a condition and does not acquire (S) in that case. It makes sense because the (S) lock will/should be released immediately and (X) lock guarantees that the row does not held any other (X) locks.
This is somewhat similar to the condition when the session may skip (S) lock if there is another (S) lock held on the same row. When you use REPEATABLEREAD/SERIALIZABLE, it needs to get (S) because it may be held longer than (X), so you’d have blocking if SELECT uses those isolation levels.
Sincerely,
Dmitri