Let’s think about the following scenario. Assuming we have a table with a lot of data. Some of the large fields in this table are rarely accessed. Same time there are constant scans on the subset of the fields.
The good example is large Articles catalog in the system where customer can search by various different columns/attributes. Let’s assume Article has the description field which holds 1000-2000 bytes in the average. Assuming customers are searching on the part of the article name, item number, price, etc etc etc and 98% of the customer activity are searching and browsing the results. Let’s say that only 2% of requests are opening the article properties and looking to the description.
Assuming all those searches will lead to the clustered index scans. As we already know, we want to minimize the number of IO operations so we want to make row as small as possible. Let’s see the example:

Now let’s run the select based on the part of the item number:
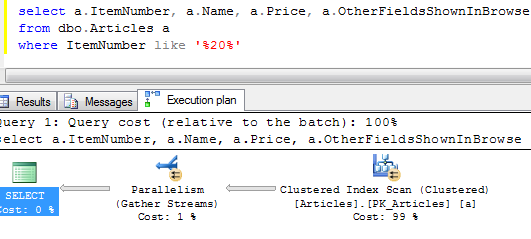

Obviously one of the ways how to improve the situation is create non-clustered index on all fields which could be in the predicate list. Problem with this approach that in most part of the cases, SQL would not be able to do the index seek. It can still do the index scan but price of this option would really depend on the number of the records in the result set – key/bookmark lookups can make it really expensive. Obviously you create covered index and include every field you need for the browse – in our case there are Name, Item Number, Price and OtherFieldsShownInBrowse, but it would make index leaf very big. In some cases though, it still acceptable and better than the solution I will show below.
Let’s change the schema and split Articles table vertically:

To simplify the situation – let’s create the view and join both tables.

Now, let’s run the previous select against view:

![]()
As we see that situation is even worse – even if we don’t need Description attribute, SQL Server joins the both tables. It does it because of the inner join. SQL Server needs to filter out all records from ArticleMain where it does not have corresponding records in ArticleDescriptions.
Let’s change it to the outer join:

Now let’s run select again:
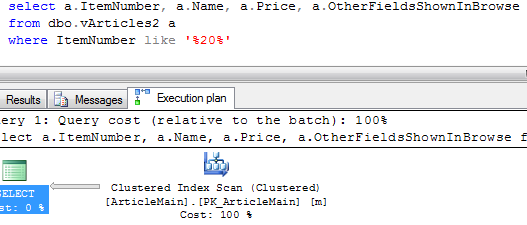
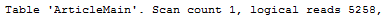
Now when we run the select, we see, that it scans ArticleMain table only. Results are much better. If we need to select fields from the both tables (for example when user want to see the properties, it would do the join.

We can even create INSTEAD OF trigger on the view in order to cover insert and update operations and simplify the client development if needed.
Again, I don’t want to say that this method is right in every case. As bare minimum you should have:
1. A lot of data in the table
2. Scans with the predicates which do not support INDEX SEEK operations and return a lot of data
3. Research if regular (covered) index would be more beneficial than this solution.
But in some cases vertical partitioning would help.