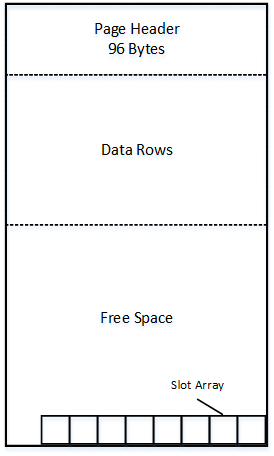
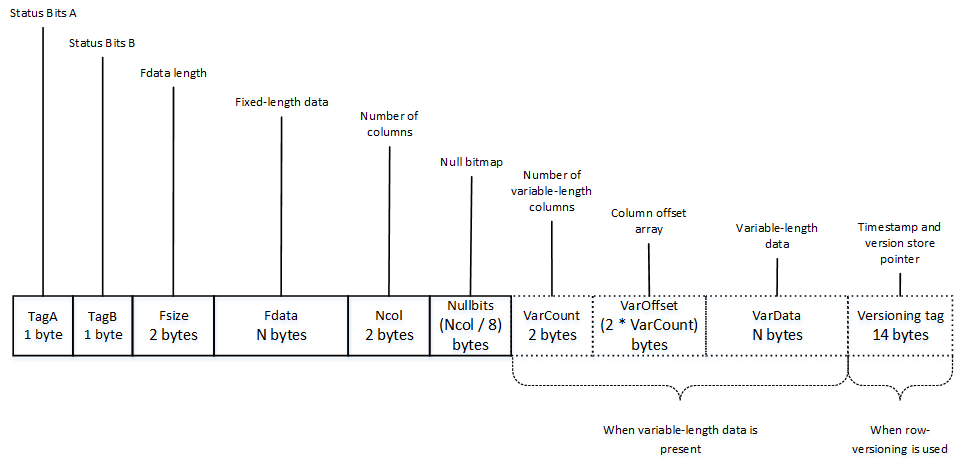
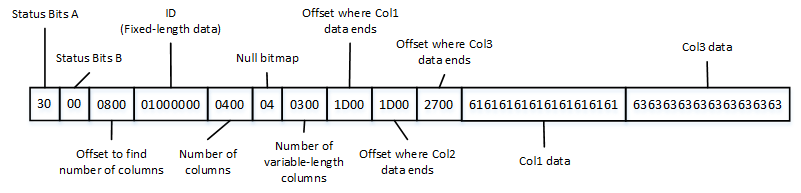
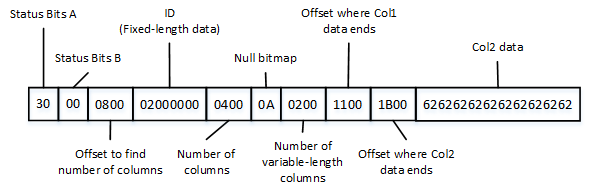
Heap tables are tables without a clustered index. The data in heap tables is unsorted. SQL Server does not guarantee nor maintain any sorting order of the data in the heap tables.
When we insert data into heap tables, SQL Server tries to fill pages as much as possible, although it does not analyze the actual free space available on a page. It uses the Page Free Space (PFS) allocation map instead. SQL Server errs on the side of caution, and it uses the low value from the PFS free space percentage tier during the estimation.
For example, if a data page stores 4,100 bytes of data, and, as result, has 3,960 bytes of free space available, PFS would indicate that the page is 51-80 percent full. SQL Server would not put a new row to the page if its size exceeds 20 percent (8,060 bytes * 0.2 = 1,612 bytes) of the page size.
Let’s look at the example and create the table with the code shown below.
create table dbo.Heap(Val varchar(8000) not null);
;with CTE(ID,Val) as
(
select 1, replicate('0',4089)
union all
select ID + 1, Val from CTE where ID < 20
)
insert into dbo.Heap(Val)
select Val from CTE;
select page_count, avg_record_size_in_bytes, avg_page_space_used_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.Heap'),0,null,'DETAILED');
01. Page Count after initial insert
At this point, the table stores 20 rows of 4,100 bytes each. SQL Server allocates 20 data pages—one page per row—with 3,960 bytes available. PFS would indicate that pages are 51-80 percent full.
As the next step, let’s inserts the small 111-byte row, which is about 1.4 percent of the page size. As a result, SQL Server knows that the row would fit into one of the existing pages (they all have at least 20 percent of free space available), and a new page should not be allocated.
insert into dbo.Heap(Val) values(replicate('1',100));
select page_count, avg_record_size_in_bytes, avg_page_space_used_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.Heap'),0,null,'DETAILED');
02. Page Count after insertion of small row
Lastly, the third insert statement needs 2,011 bytes for the row, which is about 25 percent of the page size. SQL Server does not know if any of the existing pages have enough free space to accommodate the row and, as a result, allocates the new page. You can see that SQL Server does not access existing pages by checking the actual free space and uses PFS data for the estimation.
insert into dbo.Heap(Val) values(replicate('2',2000));
select page_count, avg_record_size_in_bytes, avg_page_space_used_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.Heap'),0,null,'DETAILED');
03. Page Count after insertion of large row
That behavior leads to the situation where SQL Server unnecessarily allocates new data pages, leaving large amount of free space unused. It is not always a problem when the size of rows vary—in those cases, SQL Server eventually fills empty spaces with the smaller rows. However, especially in cases when all rows are relatively large, you can end up with large amounts of wasted space.
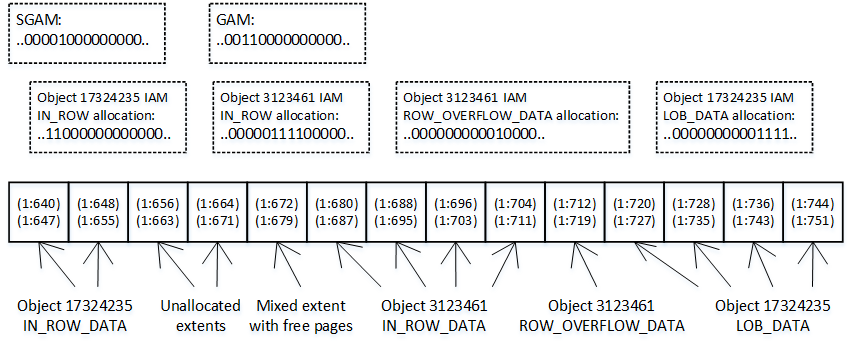
When selecting data from the heap table, SQL Server uses as Index Allocation Map (IAM) to find the pages and extents that need to be scanned. It analyzes what extents belong to the table and processes them based on their allocation order rather than on the order in which the data was inserted. You can see it in figure below.
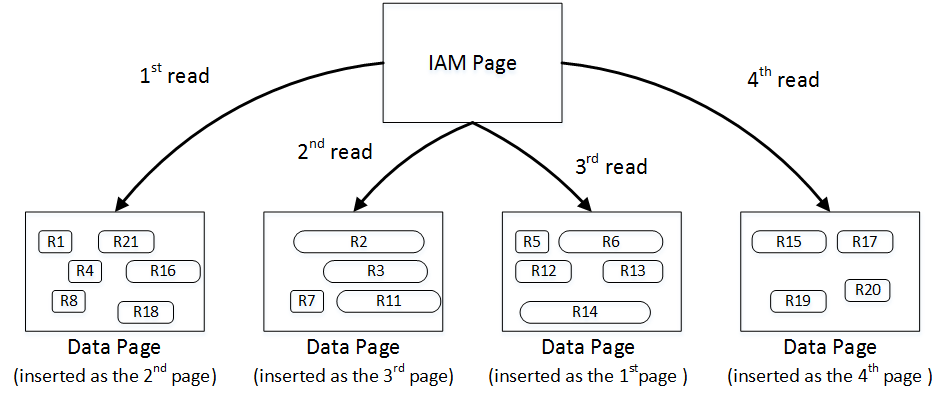
04. IAM Scan
When you update the row in the heap table, SQL Server tries to accommodate it on the same page. If there is no free space available, SQL Server moves the new version of the row to another page and replaces the old row with a special 16-byte row called a forwarding pointer. The new version of the row is called forwarded row.
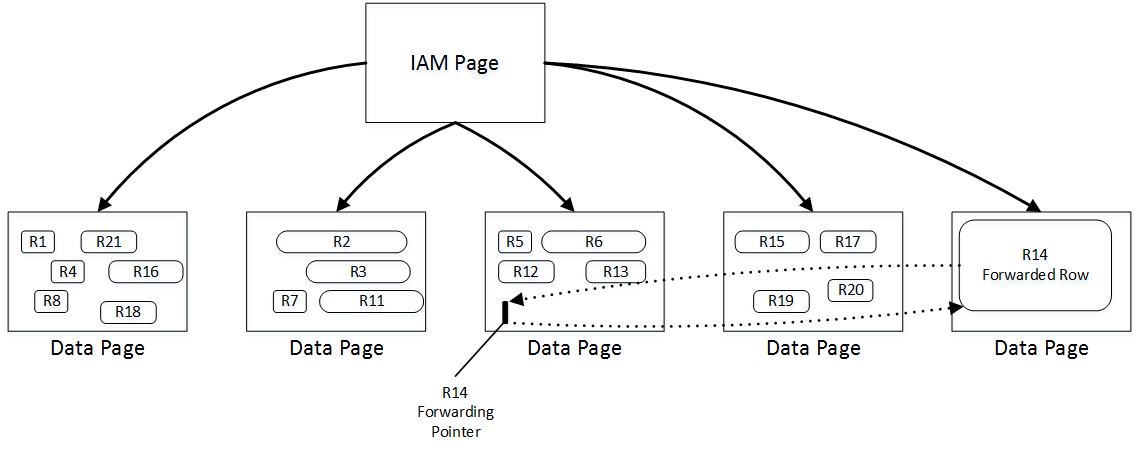
05. Forwarding Pointers
There are two main reasons why forwarding pointers are used. First, they prevent updates of nonclustered index keys, which referencing the row.
In addition, forwarding pointers helps minimize the number of duplicated reads – the situation when a single row is read multiple times during the table scan. As the example, let’s look at figure above and assume that SQL Server scans the pages in left-to-right order. Next, let’s assume that the row in page 3 was modified after the page was read at the time when SQL Server reads page 4. The new version of the row would be moved to page 5, which has yet to be processed. Without forwarding pointers, SQL Server would not know that the old version of the row had already been read, and it would read it again during the page 5 scan. With forwarding pointers, SQL Server would ignore the forwarded rows.
Forwarding pointers help minimize duplicated reads at cost of additional read operations. SQL Server follows the forwarding pointers and reads the new versions of the rows at the time it encounters them. That behavior can introduce an excessive number of I/O operations.
Let’s create the table and insert three rows there.
create table dbo.ForwardingPointers
(
ID int not null,
Val varchar(8000) null
);
insert into dbo.ForwardingPointers(ID,Val)
values
(1,null),
(2,replicate('2',7800)),
(3,null);
select page_count, avg_record_size_in_bytes, avg_page_space_used_in_percent, forwarded_record_count
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.ForwardingPointers'),0,null,'DETAILED');
set statistics io on
select count(*) as [RowCnt] from dbo.ForwardingPointers
set statistics io off
You can see results below
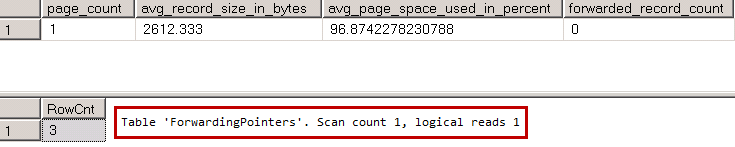
06. Forwarding Pointers: I/O without forwarding pointers
All three rows fit into the single page, and SQL Server needs to read just that page when it scans the table.
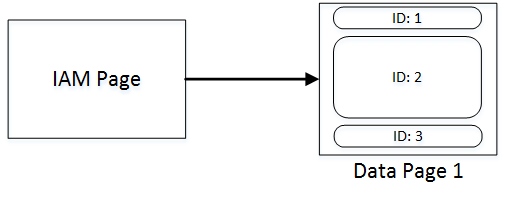
07. Page Layout without Forwarding Pointers
Let’s update two of the table rows and increase their size. The new version of the rows would not fit into the page anymore, which introduces the allocation of the two new pages and two forwarding pointers.
update dbo.ForwardingPointers set Val = replicate('1',5000) where ID = 1;
update dbo.ForwardingPointers set Val = replicate('3',5000) where ID = 3;
select page_count, avg_record_size_in_bytes, avg_page_space_used_in_percent, forwarded_record_count
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.ForwardingPointers'),0,null,'DETAILED');
set statistics io on
select count(*) as [RowCnt] from dbo.ForwardingPointers
set statistics io off

08. Forwarding Pointers: I/O with Forwarding Pointers
When SQL Server reads the forwarding pointer rows from page 1, it follows them and reads pages 2 and 3 immediately thereafter. After that, SQL Server reads those pages one more time during the regular IAM scan process. As a result, we have five read operations, even though our table has just three data pages.
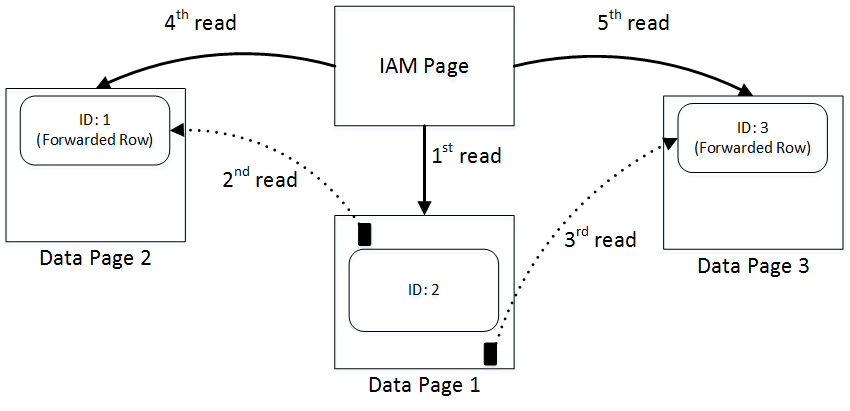
09. Page Layout and I/O with Forwarding Pointers
It does not look as bad in case of the small table. Let’s look at the same issue in case, when table has more rows. Let’s insert 65,536 rows to our table.
truncate table dbo.ForwardingPointers go ;with N1(C) as (select 0 UNION ALL select 0) -- 2 rows ,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows ,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows ,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows ,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows ,IDs(ID) as (select row_number() over (order by (select NULL)) from N5) insert into dbo.ForwardingPointers(ID) select ID from IDs; select page_count, avg_record_size_in_bytes, avg_page_space_used_in_percent, forwarded_record_count from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.ForwardingPointers'),0,null,'DETAILED'); set statistics io on select count(*) as [RowCnt] from dbo.ForwardingPointers set statistics io off

10. Large table: I/O without Forwarding Pointers
As you see, there are 106 pages in the table and as result, SQL Server performs 106 reads during IAM scan. Let’s update our table and introduce forwarding pointers.
update dbo.ForwardingPointers set Val = replicate('a',500);
select page_count, avg_record_size_in_bytes, avg_page_space_used_in_percent, forwarded_record_count
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.ForwardingPointers'),0,null,'DETAILED');
set statistics io on
select count(*) as [RowCnt] from dbo.ForwardingPointers
set statistics io off

11. Large Table: I/O with Forwarding Pointers
Now our table has 4,461 pages however it requires almost 70 thousand reads to perform a scan. As you see, the large number of the forwarding pointers leads to extra I/O operations and significantly reduces the performance of the queries accessing the data.
When the size of the forwarded row is reduced by another update and the data page with forwarding pointer has enough space to accommodate updated version of the row, SQL Server might move it back to original data page and remove the forwarding pointer. Nevertheless, the only reliable way to get rid of the all forwarding pointers is by rebuilding the heap table. You can do that by using an ALTER TABLE REBUILD statement or by creating and dropping a clustered index on the table.
Heap tables can be useful in staging environment where you want to import a large amount of data into the system as fast as possible. Inserting data into heap tables can often be faster than inserting it into tables with clustered indexes. Nevertheless, during a regular workload, tables with clustered indexes usually outperform heap tables due to their suboptimal space control and forwarding pointers.