Clustered columnstore indexes is the great technology that dramatically improve performance of Data Warehouse queries. The data in those indexes is stored on per-column basis, and it is heavily compressed and optimized for the large scans and complex analytical queries.
The same time, columnstore indexes do not handle OLTP workload with point-lookup and small range scans well. Starting with SQL Server 2016, however, we can create regular B-Tree nonclustered indexes on such tables. This allows us to get the best from the both worlds and utilize the technology in mixed (OLTP+DW) environments.
The typical columnstore table is usually large and contains hundreds of millions or even billions of rows. Think about large fact tables in the data warehouses or huge transactional tables in OLTP systems. Those tables are usually partitioned. Besides usual reasons (Availability, Maintainability, etc), partitioning helps with the data load – it is easier to perform ETL in the staging table and import data through partition switch.
And here comes the problem. If you run OLTP query against partitioned clustered columnstore table and end up with the execution plan that uses index intersection of nonclustered B-Tree indexes, you may get incorrect results.
Let’s look at the example and create a small table. For simplicity sake, the table would have just two partitions and two rows – one per partition. I am also going to create two nonclustered indexes there.
create partition function pfOrders(datetime)
as range right
for values('2019-09-01');
create partition scheme psOrders
as partition pfOrders
all to ([PRIMARY])
go
create table dbo.Orders
(
OrderId int not null,
OrderDate datetime not null,
CustomerId int not null,
ShipDate date not null,
Amount money not null
)
on psOrders(OrderDate);
go
insert into dbo.Orders(OrderId, OrderDate
,CustomerId, ShipDate, Amount)
values
(1,'2019-08-15',1,'2019-08-17',9.99)
,(2,'2019-09-10',2,'2019-09-15',19.99);
go
create clustered columnstore index CCI_Orders
on dbo.Orders
on psOrders(OrderDate);
create nonclustered index IDX_Orders_CustomerId
on dbo.Orders(CustomerId);
create nonclustered index IDX_Orders_ShipDate
on dbo.Orders(ShipDate);
select * from dbo.Orders;
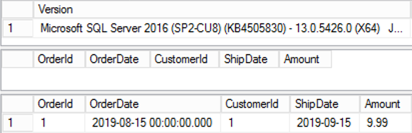
Figure 1 illustrates two rows that we have in the table.

As the next step, let’s run queries below. I am running two SELECT statements that should not return any data based on query predicates. The first SELECT will use the regular table (clustered columnstore index) scan. In the second SELECT, I am forcing SQL Server to use two nonclustered indexes with the index hint, which will trigger index intersection.
select @@VERSION as [Version];
select *
from dbo.Orders
where CustomerId = 1 and ShipDate = '2019-09-15';
select *
from dbo.Orders with (index (IDX_Orders_CustomerId, IDX_Orders_ShipDate))
where CustomerId = 1 and ShipDate = '2019-09-15';
And here we have the issue, as you can see in Figure 2, the second query returns incorrect results. You may notice that data does not belong to any particular row – ShipDate column belongs to the row with OrderID=2 while all other columns belong to the row with OrderID = 1.
Even though we executed those queries in SQL Server 2016 SP2 CU8, the same problem exists in many other builds including SQL Server 2017 RTM – CU 16 and in SQL Server 2019 RC1. And of course, it exists in SQL Server 2016 RTM/SP1 builds that are out of support.
Figure 3 illustrates execution plan of the query that produces incorrect results. Index intersection performs Index Seek operations on both nonclustered indexes and joins the results based on row-id of selected rows. In clustered columnstore indexes, the row-id is, basically, the columnstore locator, which is the combination of (row-group-id, offset-within-row-group) values.
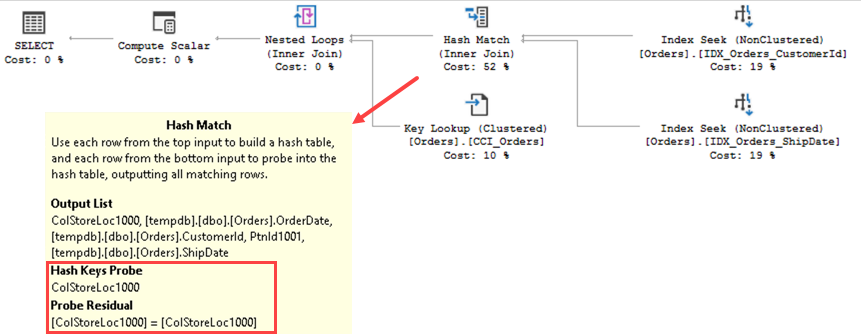
The issue here, that partition-id is not present as the predicate. The columnstore locator is not unique across partitions and, therefore, this join leads to incorrect results.
Let’s repeat our test after installing SQL Server 2016 SP2 CU9 update. At this time, the results are correct as shown in Figure 4.
NOTE: Microsoft unpublished SQL Server SP2 CU9 due to the issues with the uninstaller. The new CU10 has been published yesterday and it contains the fix for the bug.
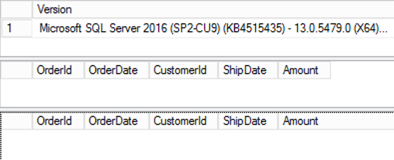
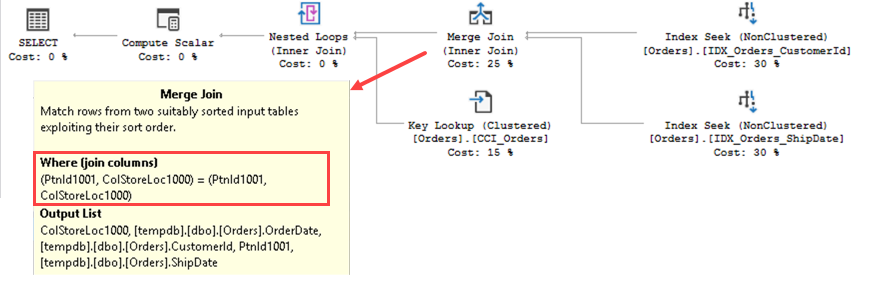
Figure 5 illustrates the new execution plan. As you see, Hash join has been replaced by the Merge join. But most importantly, partition-id is now present as part of the join predicate.
We can force the “old” execution plan with HASH JOIN query hint as shown in the code below.
select *
from dbo.Orders with (index (IDX_Orders_CustomerId, IDX_Orders_ShipDate))
where CustomerId = 1 and ShipDate = '2019-09-15'
option (hash join, loop join)
Figure 6 illustrates the execution plan. As you can see, now the hash predicate also includes partition-id, which leads to correct results.
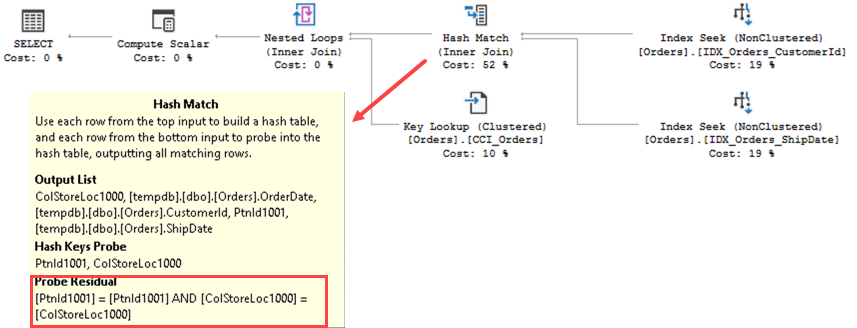
I consider this bug to be extremely critical and urge you to patch SQL Server as soon as possible. This is the great example that illustrates importance of keeping our environments up to date.
The bug is fixed in:
• Latest SQL Server 2016 SP2 CU. Currently CU10
• Latest SQL Server 2017 CU. Currently CU17
• KB Number: 4519366
It will obviously also going to be fixed in SQL Server 2019.
Source code is available for download.
PS. Big thanks to Leo Schmidt for reporting, and Vassilis Papadimos and Joe Sack for addressing the issue!