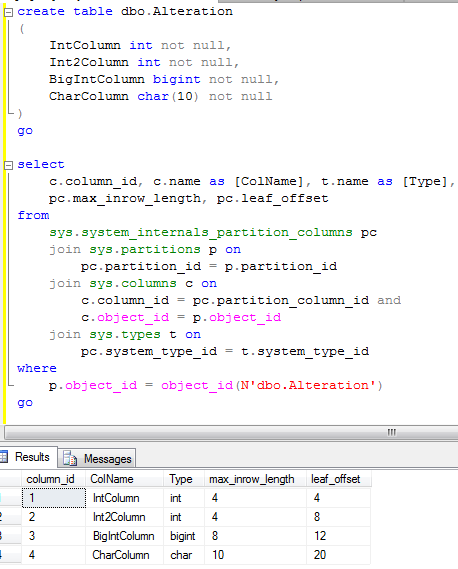
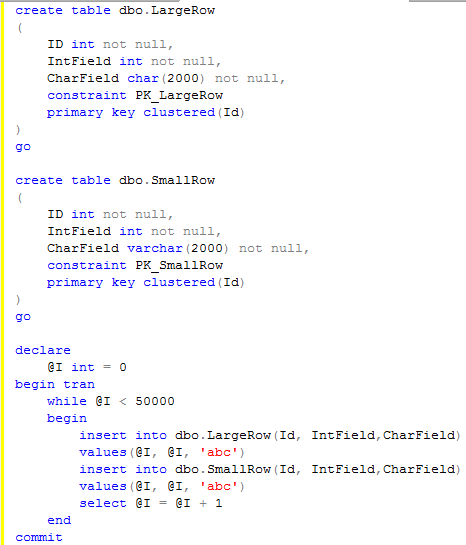
Let’s talk how SQL Server stores LOB data. Let’s start with restricted-length large objects – objects which are less or equal than 8000 bytes. This would include varchar, nvarchar, varbinary, CLR data types and sql_variants.
Let’s try to create the table with large varchar columns and insert some data:

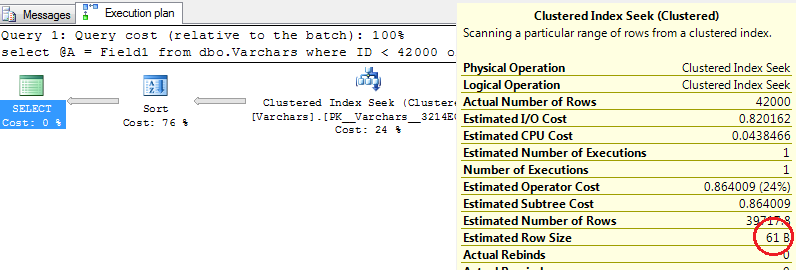
As you can see, table created successfully and row with size slightly bigger than 8,800 bytes have been inserted. Let’s check what data pages do we have for this table
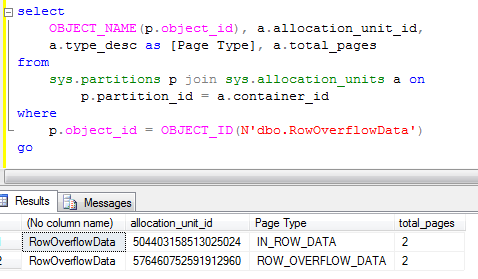
As you can see, there are 2 types of the pages – IN_ROW_DATA and ROW_OVERFLOW_DATA. You need to deduct 1 from total pages count (IAM pages), so in this case you see 1 page for IN_ROW_DATA (populated with Field1, Field2, Field3 column data) and 1 page for ROW_OVERFLOW_DATA (for Field4 column data).
So restricted-length LOBs are stored either completely in-row or in row-overflow pages if does not fit. In the second case, there is 24 bytes pointer + 2 byte in offset array in the row.
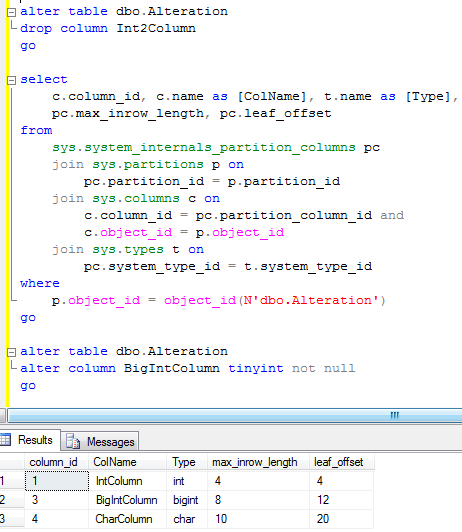
Let’s see what happened if you update the row:
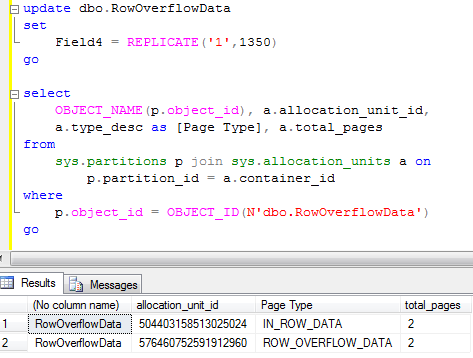
Now the row size is slightly less than 8,000 bytes so row “should” fit on the single page. Although it still uses row-overflow page. SQL Server does not bother to check. In real life the threshold is about 1000 bytes. Let’s see that.
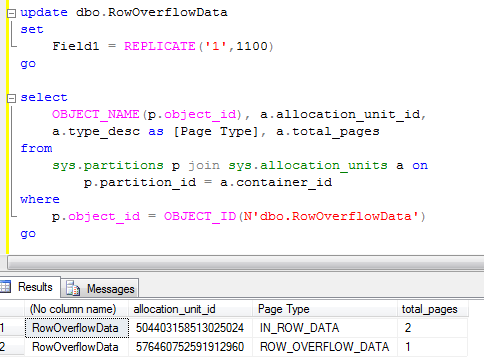
As you see, we updated another field for more than 1,000 bytes and row_overflow page is gone.
For unrestricted-length data (text, ntext, image), the situation is different. SQL Server also stores it on the own set of the pages with 16 bytes (by default) pointer in the row. The data itself will be organized in B-TREE matter similar to regular indexes with pointers to the actual blocks of data. I don’t show the examples here – but you get an idea. The type of the data pages would be TEXT_MIXED – if page shares the data from the multiple rows or TEXT_DATA if entire chunch of the data on the page is the single value.
What also worth to mention is “text in row” table option. This option controls if some part of the LOB data needs to be stored in the row.
And finally the (max) types. This is quite simple. If the size of the data <= 8000 bytes, it stores as restricted-length objects in the row_overflow pages. If more – it stores as unrestricted-length data.
You can create quite big rows with a lot of data on the row-overflow and text_mixed/text_data pages. But don’t forget, that SQL Server will need to read other page(s) when accessing the row. Not really good in terms of performance.