The 8,060-byte maximum row size limit is, perhaps, one of the biggest roadblocks in widespread In-Memory OLTP adoption. This limitation essentially prevents you from using (max) data types along with CLR and system data types that require off-row storage, such as XML, geometry, geography and a few others. Even though you can address this by changing the database schema and T-SQL code, these changes are often expensive and time consuming.
When you encounter such a situation, you should analyze if LOB data types are required in the first place. It is not uncommon to see a column that never stores more than a few hundred characters defined as (n)varchar(max). Consider an Order Entry system and DeliveryInstruction column in the Orders table. You can safely limit the size of the column to 500-1,000 characters without compromising the business requirements of the system.
Another example is a system that collects some semistructured sensor data from the devices and stores it in the XML column. If the amount of semistructured data is relatively small, you can store it in varbinary(N) column, which will allow you to move the table into memory.
Unfortunately, sometimes it is impossible to change the data types and you have to keep LOB columns in the tables. Nevertheless, you have a couple options to proceed.
The first approach is to split data between two tables, storing the key attributes in memory-optimized and rarely-accessed LOB attributes in on-disk tables. Again, consider the situation where you have an Order Entry system with the Products table defined as shown in Listing below
create table dbo.Products
(
ProductId int not null identity(1,1),
ProductName nvarchar(64) not null,
ShortDescription nvarchar(256) not null,
Description nvarchar(max) not null,
Picture varbinary(max) null,
constraint PK_Products
primary key clustered(ProductId)
)
As you can guess, in this scenario, it is impossible to change the data types of the Picture and Description columns, which prevents you from making the Products table memory-optimized. However, you can split that table into two, as shown below. The Picture and Description columns are stored in an on-disk table while all other columns are stored in the memory-optimized table. This approach will improve performance for the queries against the ProductsInMem table and will allow you to access it from natively compiled stored procedures in the system.
create table dbo.ProductsInMem
(
ProductId int not null identity(1,1)
constraint PK_ProductsInMem
primary key nonclustered hash
with (bucket_count = 65536),
ProductName nvarchar(64)
collate Latin1_General_100_BIN2 not null,
ShortDescription nvarchar(256) not null,
index IDX_ProductsInMem_ProductName
nonclustered(ProductName)
)
with (memory_optimized = on, durability = schema_and_data);
create table dbo.ProductAttributes
(
ProductId int not null,
Description nvarchar(max) not null,
Picture varbinary(max) null,
constraint PK_ProductAttributes
primary key clustered(ProductId)
);
Unfortunately, it is impossible to define a foreign key constraint referencing a memory-optimized table, and you should support referential integrity in your code. We have already looked at one of the possible approaches in my previous blog post.
You can hide some of the implementation details from the SELECT queries by defining a view as shown below. You can also define INSTEAD OF triggers on the view and use it as the target for data modifications; however, it is more efficient to update data in the tables directly.
create view dbo.Products(ProductId, ProductName,
ShortDescription, Description, Picture)
as
select
p.ProductId, p.ProductName, p.ShortDescription
,pa.Description, pa.Picture
from
dbo.ProductsInMem p left outer join
dbo.ProductAttributes pa on
p.ProductId = pa.ProductId
As you should notice, the view is using an outer join. This allows SQL Server to perform join elimination when the client application does not reference any columns from the ProductAttributes table when querying the view. For example, if you ran SELECT ProductId, ProductName from dbo.Products, you would see the execution plan as shown in Figure 1. As you can see, there are no joins in the plan and the ProductAttributes table is not accessed.
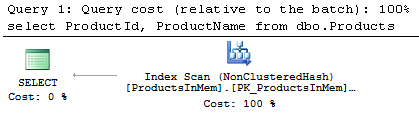
1. Execution Plan with Join Elimination
You can use a different approach and store LOB data in memory-optimized tables, splitting it into multiple 8,000-byte chunks. You can use the table similar to what is defined below.
create table dbo.LobData
(
ObjectId int not null,
PartNo smallint not null,
Data varbinary(8000) not null,
constraint PK_LobData
primary key nonclustered hash(ObjectID, PartNo)
with (bucket_count=1048576),
index IDX_ObjectID
nonclustered hash(ObjectID)
with (bucket_count=1048576)
)
with (memory_optimized = on, durability = schema_and_data)
Listing below demonstrates how to insert XML data into the table using T-SQL code in interop mode. It uses an inline table-valued function called dbo.SplitData that accepts the varbinary(max) parameter and splits it into multiple 8,000-byte chunks.
create function dbo.SplitData
(
@LobData varbinary(max)
)
returns table
as
return
(
with Parts(Start, Data)
as
(
select 1, substring(@LobData,1,8000)
where @LobData is not null
union all
select
Start + 8000
,substring(@LobData,Start + 8000,8000)
from Parts
where len(substring(@LobData,Start + 8000,8000)) > 0
)
select
row_number() over(order by Start) as PartNo
,Data
from
Parts
)
go
-- Test Data
declare
@X xml
select @X =
(select * from master.sys.objects for xml raw)
insert into dbo.LobData(ObjectId, PartNo, Data)
select 1, PartNo, Data
from dbo.SplitData(convert(varbinary(max),@X))
On the side note, dbo.SplitData function uses recursive CTE to split the data. Do not forget that SQL Server limits the CTE recursion level to 100 by default. You need to specify OPTION (MAXRECURSION 0) in the statement that uses the function in case of very large inputs.
Figure 2 shows the contents of the LobData table after the insert.

2. Content of LobData table after insert
You can construct original data using FOR XML PATH method as shown below. Alternatively, you can develop a CLR aggregate and concatenate binary data there.
;with ConcatData(BinaryData)
as
(
select
convert(varbinary(max),
(
select convert(varchar(max),Data,2) as [text()]
from dbo.LobData
where ObjectId = 1
order by PartNo
for xml path('')
),2)
)
select convert(xml,BinaryData)
from ConcatData
The biggest downside of this approach is the inability to split and merge large objects in natively compiled stored procedures due to the missing (max) parameters and variables support. You should use the interop engine for this purpose. However, it is still possible to achieve performance improvements by moving data into memory even when the interop engine is in use.
This approach is also beneficial when memory-optimized tables are used just for the data storage, and all split and merge logic is done inside the client applications. I will show you such an example in my next blog post.