SQL Server logically groups eight pages into 64KB units called extents. There are two types of extents available: Mixed extents store data that belongs to different objects. Uniform extents store the data for the same object.
When a new object is created, SQL Server stores first eight object pages in mixed extents. After that, all subsequent space allocation for that object is done with uniform extents.
SQL Server uses special kind of pages, called Allocation Maps, to track extent and page usage in a file. There are several different types of allocation maps pages in SQL Server.
Global Allocation Map (GAM) pages track if extents have been allocated by any objects. The data is represented as bitmaps where each bit indicates the allocation status of an extent. Zero bits indicate that the corresponding extents are in use. The bits with a value of one indicate that the corresponding extents are free. Every GAM page covers about 64,000 extents, or almost 4GB of data. This means that every database file has one GAM page for about 4GB of file size.
Shared Global Allocation Map (SGAM) pages track information about mixed extents. Similar to GAM pages, it is a bitmap with one bit per extent. The bit has a value of one if the corresponding extent is a mixed extent and has at least one free page available. Otherwise, the bit is set to zero. Like a GAM page, SGAM page tracks about 64,000 extents, or almost 4GB of data.
SQL Server can determine the allocation status of the extent by looking at the corresponding bits in GAM and SGAM pages. Figure below shows the possible combinations of the bits.

01. GAM and SGAM bit statuses
When SQL Server needs to allocate a new uniform extent, it can use any extent where a bit in the GAM page has the value of one. When SQL Server needs to find a page in a mixed extent, it searches both allocation maps looking for the extent with a bit value of one in a SGAM page and the corresponding zero bit in a GAM page. If there are no such extents available, SQL Server allocates the new free extent based on the GAM page, and it sets the corresponding bit to one in the SGAM page.
Every database file has its own chain of GAM and SGAM pages. The first GAM page is always the third page in the data file (page number 2). The first SGAM page is always the fourth page in the data file (page number 3). The next GAM and SGAM pages appear every 511,230 pages in the data files which allows SQL Server to navigate through them quickly when needed.
SQL Server tracks the pages and extents used by the different types of pages (in-row, row-overflow, and LOB pages), that belong to the object with another set of the allocation map pages, called Index Allocation Map (IAM). Every table/index has its own set of IAM pages, which are combined into separate linked lists called IAM chains. Each IAM chain covers its own allocation unit – IN_ROW_DATA, ROW_OVERFLOW_DATA, and LOB_DATA.
Each IAM page in the chain covers a particular GAM interval and represents the bitmap where each bit indicates if a corresponding extent stores the data that belongs to a particular allocation unit for a particular object. In addition, the first IAM page for the object stores the actual page addresses for the first eight object pages, which are stored in mixed extents.
The figure below shows a simplified version of the allocation map pages bitmaps.
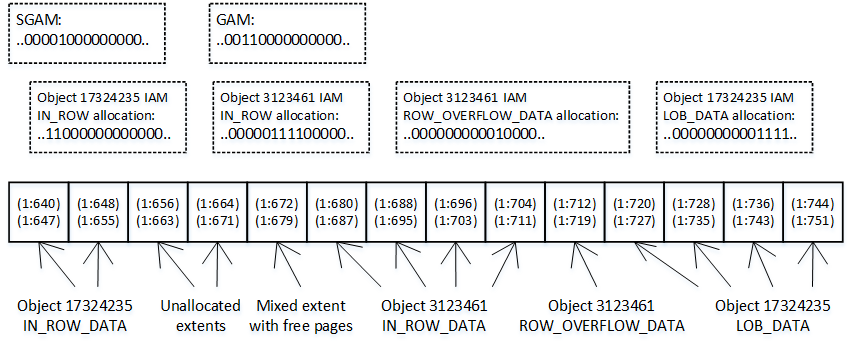
02. Allocation maps
Partitioned tables and indexes have separate IAM chains for every partition. In fact, you can consider non-partitioned table as the partitioned with just a single partition.
There is another type of allocation map page called Page Free Space (PFS). Despite the name, PFS pages track a few different things. We can call PFS as a byte-mask, where every byte stores information about a specific page, as shown below.
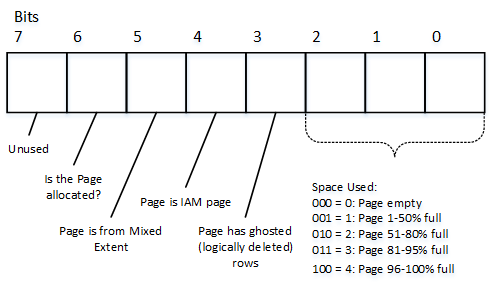
03. PFS byte structure
The first three bits in the byte indicate the percent of used space on the page. SQL Server tracks the used space for row-overflow and LOB data, as well as for in-row data in the heap tables. These are the only cases when amount of free space on the page matters.
When you delete a data row from the table, SQL Server does not remove it from the data page but rather marks the row as deleted. Bit 4 indicates if the page has logically deleted (ghosted) rows.
Bit 5 indicates if the page is an IAM page. Bit 6 indicates whether or not the page is in the mixed extent. Finally, bit 7 indicates if the page is allocated.
Every PFS page tracks 8,088 pages or about 64MB of data space. It is always the second page (page 1) in the file and every 8,088 pages thereafter.
There are two more types of allocation map pages. The seventh page (page 6) in the file is called a Differential Changed Map (DCM). These pages keep track of extents that have been modified since the last FULL database backup. SQL Server uses DCM pages when it performs DIFFERENTIAL backups.
The last allocation map is called Bulk Changed Map (BCM). It is eighth page (page 7) in the file, and it indicates what extents have been modified in minimally-logged operations since the last transaction log backup. BCM pages are used only with a BULK_LOGGED database recovery model.
Both, DCM and BCM pages are the bitmasks that cover 511,230 pages in the data file.
Next: HEAP tables