Last week we started to discuss table partitioning and specified a few cases when partition is really useful. Today I want to focus on the downsides of the process.
First, column used in the partition function needs to be included into the clustered index (and as result all non-clustered indexes). Unless this column is ALREADY part of the clustered index, it means you’re increasing non-clustered index row size. And think about it – you typically partition the large table with millions of rows (what is the reason to partition the small tables?). With such number of rows, index size matters. From both – storage size prospective and index performance.
Another interesting thing – that unless you have rare case when you don’t want index to be aligned, partitioned column should be included into the index definition. It would not increase the row size (CI values are part of the NCI rows anyway), but it could break the indexes you’re using to check uniqueness of the data.
Next, you cannot do partition switch if table is replicated with SQL Server 2005. Fortunately SQL Server 2008 addresses this issue.
Next, you cannot do partition switch if table is referenced by other tables. Typically it’s not an issue for the large transaction tables but still – it could happen.
And now let’s see the worst one. When index is aligned, the data is distributed across multiple partitions. And regular TOP operator does not work anymore. Let’s see that in example. First let’s create the table and populate it with some data.

Now, let’s run the select that get TOP 100 rows:

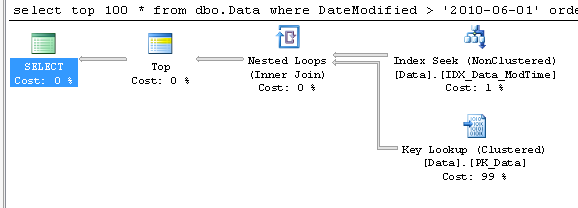
As you can see the plan is straight-forward – TOP and INDEX SEEK.
Now let’s partition that table by DateCreated.

And run the same select.
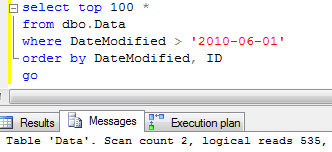
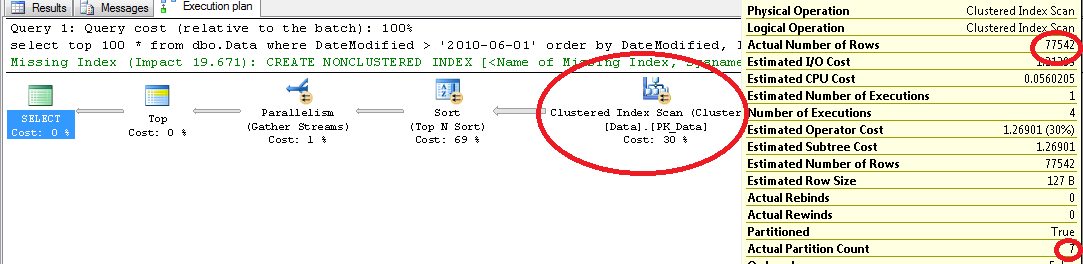
Surprisingly it uses clustered index scan. Let’s try to force SQL to use index:
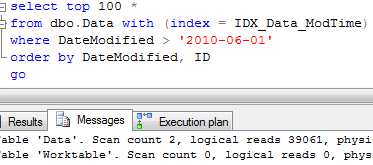

As you can see, it introduces 100 times more reads. Let’s think about it for a minute. Why does it happen?
Think about first example with non-partitioned table. Index data is sorted by DateModified and ID.
![]()
So when you run the select like above, SQL Server needs to locate the first row in the index and continue to scan index forward for the next 100 rows. Sweet and simple.
Now let’s think about partition case. We partition index by DateCreated – 3rd column in the index. This column affects the placement of the index row to specific partition. And index is sorted by DateModified and ID only within the partition. See example below – you can see that the row with DateModified = 2010-01-02 can be placed on the first partition because it controlled by DateCreated.
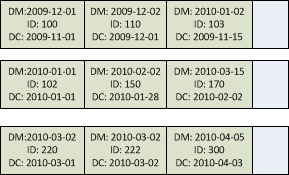
Now let’s think how SQL Server runs the select if it uses the index. For each partition on the table it selects the first row that matches the predicates and scan forward entire partition up to the end. Next, it merges results from all partitions, does the sort and next selects TOP N rows from all the partitions. As you can see, it introduces huge performance hit. I wish SQL Server would be smart enough to scan only N row from each partition, but unfortunately it’s not the case. It scans everything.
Unfortunately there is no simple workaround. This is something you need to live with.
Update (2011-12-18) – Well, there is the workaround that would work in some cases. Check it out here: http://aboutsqlserver.com/2011/12/18/sunday-t-sql-tip-select-top-n-using-aligned-non-clustered-index-on-partitioned-table/
Update (2012-03-11) – Another, more clean and generic workaround – http://aboutsqlserver.com/2012/03/11/sunday-t-sql-tip-aligned-non-clustered-indexes-on-partitioned-table-again/
Source code is available for download.
Next week we will talk about sliding window implementation.
hi thaks for sharing your post over here Nice…