Last time we took a look at the structure of the indexes. Now let’s talk about index usage in general
Assume you run the query that requires the clustered index scan. Obviously it would require SQL Server to read every data page of the clustered index for the processing. Same time, number of physical reads would be much less than the logical reads. SQL Server uses technique called “Read ahead”. In the nutshells, SQL Server reads up to 64 data pages during the single read operation. So next time SQL Server needs to read the next data page, it most likely would be present in the buffer cache. It still introduces the logical read but obviously would not produce the physical read.
Now let’s think about the operation that scans non non-clustered index. As we know, SQL Server needs to traverse clustered index b-tree for every key/bookmark lookup operation. Even if read-ahead technique would work for the non-clustered index, actual table (clustered index) data could reside anywhere in the data files. So this is basically random IO operation.
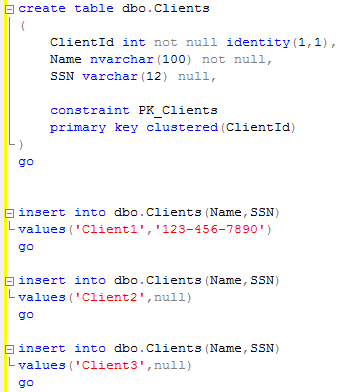
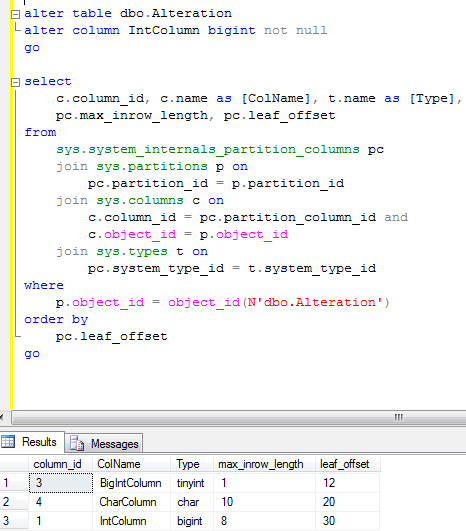
Let’s see the example. First of all, let’s create the following table:

Let’s evenly distribute the data for the Name column with the combination of: AAA, AAB, … ZZZ adding 5 rows per each combination and create the non-clustered index on that field

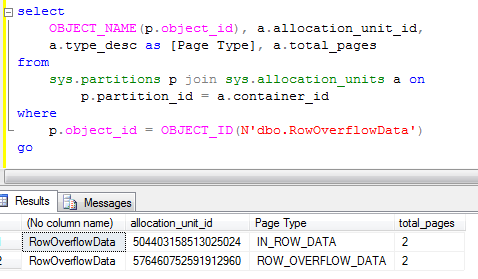
Let’s see some statistics.

As you can see the table has 87880 rows. Clustered index leaf level has 4626 pages and non-clustered index leaf level has 296 pages. Let’s do the tests.
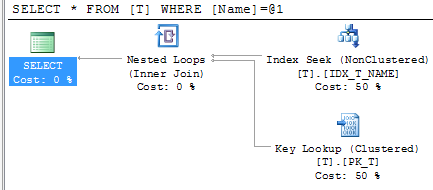
First test. Let’s select rows with Name = ‘ABC’
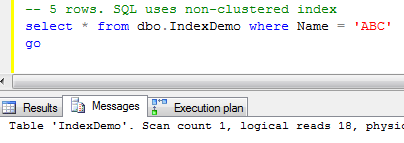

As you see it returns 5 rows only and leads to 18 logical reads. SQL Server would use non-clustered index for this case.
Second test. Let’s select rows with name starting with ‘AB’
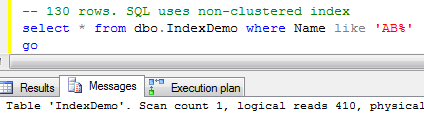
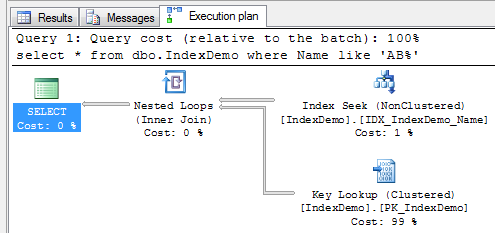
As you see it returns 130 rows and produces 410 logical reads. SQL Server uses non-clustered index. Another thing worth to mention that 99% of the cost of the query is the key lookup.
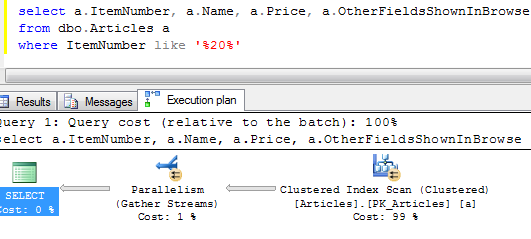
Next test. Let’s select rows with name starting with ‘A’. Basically it returns 1/26th of the rows which is about 3.8%
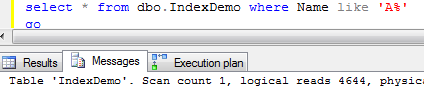

As you can see, SQL Server decided to do the clustered index scan which leads to 4644 logical reads.
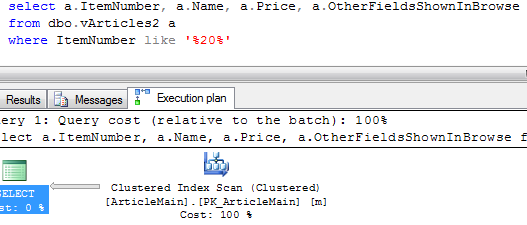
Let’s run the same select forcing SQL Server to use non-clustered index
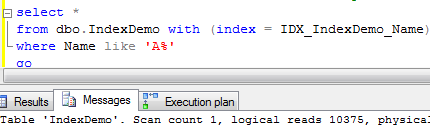
As you can see, it produces 10375 logical reads – 2+ times more than clustered index scan. And without any help from read ahead.
So you see – threshold when non-clustered index scan becomes more expensive is really small. SQL Server will not use non-clustered index with key/bookmark lookup in the case if it expects iterator to return more than a few % of the total rows from the table.
Where does it leave us? Make the index highly selective.
Code can be downloaded from here